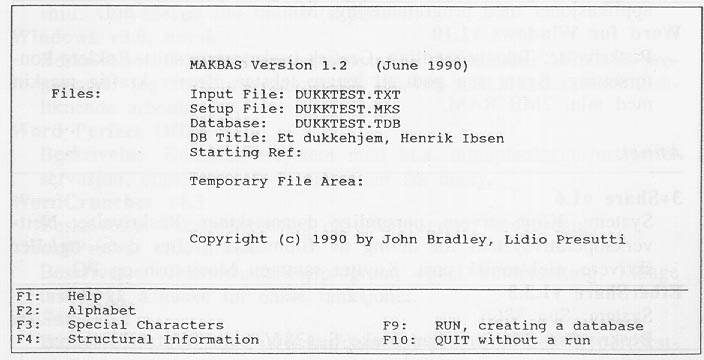
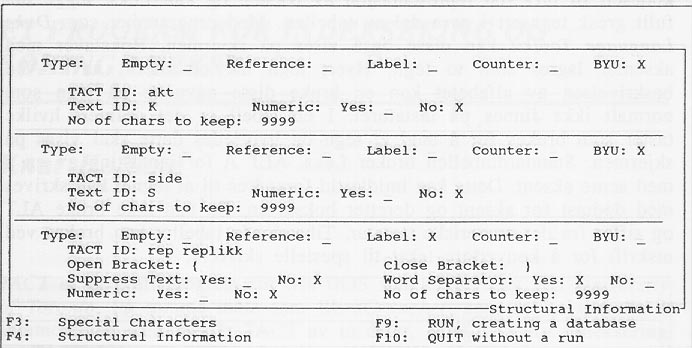
Etter at alle opplysningene er gitt, kan en starte selve indekseringen og MAKBAS viser hvor stor andel av teksten som til en hver tid er behandlet. Hvis en forandrer parameterne må en indeksere teksten på ny. Men en får ikke gjøre dette dersom det allerede eksisterer en indeks. Da må en avslutte MAKBAS og slette denne filen i DOS. Parametrene blir heller ikke lagret dersom en avslutter programmet uten å indeksere. Dette virker noe tungvint. Dersom tekstfilen er for stor, må en dele denne opp i mindre deler og indeksere disse hver for seg. Inntil 4 deler kan deretter flettes sammen med programmet MERGEBAS. Både MAKBAS og MERGEBAS kan kalles opp i BAT filer, slik at en kan automatisere indekseringen av store tekster. Den optimale størrelsen på en tekstfil er ca. 200 KB.
I motsetning til WordCruncher samler MAKBAS tekst og indeks i n fil, kalt tekstdatabase. For en råtekst på 156 KB (Ibsens "Et dukkehjem"), utgjør denne filen 444 KB, dvs. en økning på ca. 185% (mot 75% for WordCruncher). Indekseringen av tekst går noe hurtigere ved TACT enn ved WordCruncher. På en standard PC tar indeksering av en fil på 156 KB 20:18 minutter, mot 31:24 for WordCruncher. Tilsvarende tall for en rask AT maskin er 6:22 og 13:48 (7:12 for WordCruncher ved bruk av disk cache) og for en 386-maskin 2:35 og 8:48 (2:36 med disk cache). MAKBAS gjør bruk av all ledig hukommelse opptil 640 KB og en bør derfor indeksere uten residente programmer eller nettverksdrivere.
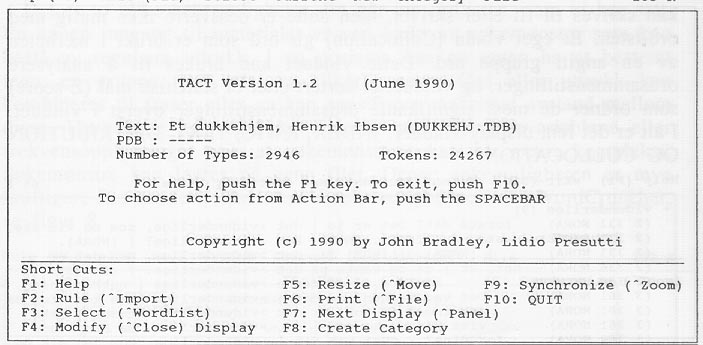
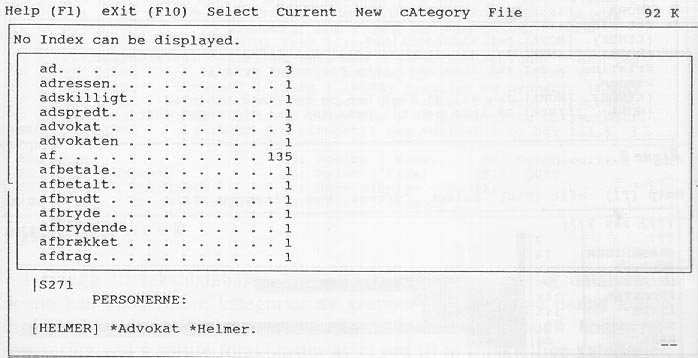
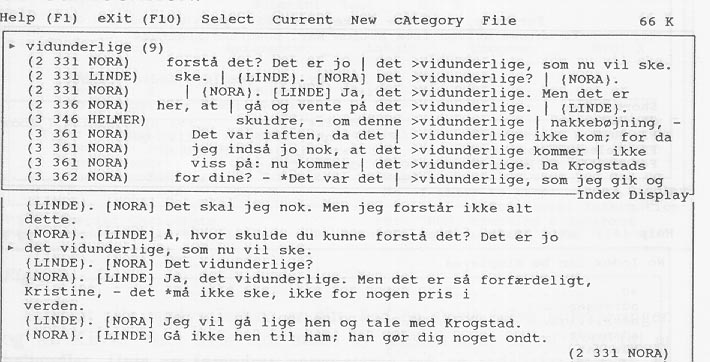
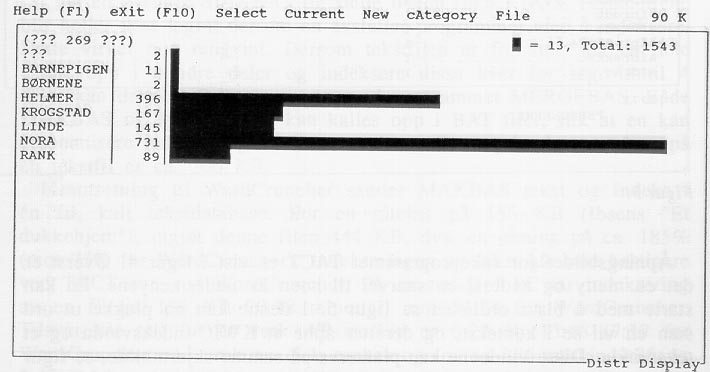
Åpningsbildet for søkeprogrammet TACT er vist i figur 4. Øverst er det en meny og nederst en snarvei til noen av undermenyene. En kan starte med å bla i ordlisten se figur 5. I denne kan en plukke ut ord som en vil se i kontekst, og deretter åpne et KWIC-indeksvindu og et tekstvindu. Disse vinduene kan plasseres på samme skjermbilde, se figur 6. Innenfor vinduene kan en bla med piltastene. Det er også mulig å se hvorledes forekomstene av en gruppe ord fordeler seg etter en referansekategori eller merkelapp, se figur 7. De forskjellige vinduer kan skrives til fil eller skriver, men dette er dessverre ikke mulig med ordlisten. Et eget vindu (Collocation) gir ord som er brukt i nærheten av en angitt gruppe ord. Dette vinduet kan brukes til å analysere ordsammenstillinger, og vinduet er sortert etter et statistisk mål (Z-score) som ordner de mest signifikante ordsammenstillinger øverst i vinduet. I alt er det fem display-vinduer: INDEX, KWIC, TEXT, DISTRIBUTION OG COLLOCATION.
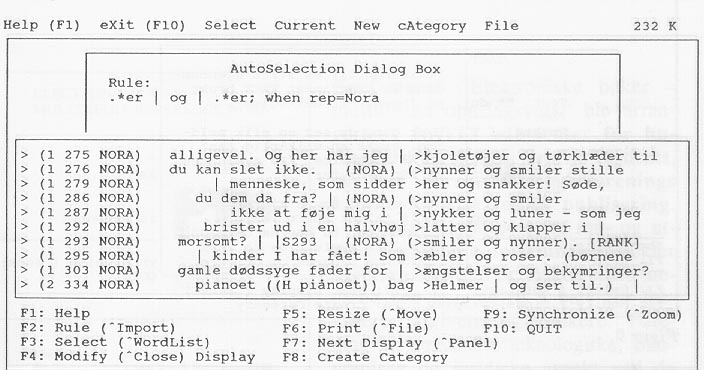
Det er to ulike søkemuligheter. n går via ordlisten, som vi har sett. En annen inngang til materialet er ved hjelp av søkemønstre som kan bestå av regulære uttrykk. I en posisjon kan en enten ha et bestemt tegn, en gruppe tegn eller et vilkårlig tegn. Ord eller uttrykk kan kombineres til fraser eller en kan spesifisere maksimal avstand mellom disse. Uttrykkene kan også kombineres med referansevariablene eller frekvensopplysninger slik at søkemønsteret kan bli svært komplekst. Søkemønstre kan lagres på egne filer. Denne søkemuligheten er mye kraftigere enn den forholdsvis enkle søkemulighet som er i WordCruncher, se figur 8.
I tillegg til tekstdatabasen kan en opprette en personlig database. I denne kan en definere kategorier av grupper av ord og på denne måten lage en tesaurus. Det er også mulig å foreta en manuell homografseparering ved å splitte forekomster av et ord til to forskjellige kategorier.
TACT inneholder en mulighet til å lagre tastetrykk på en fil (script) og senere få utført disse. I denne filen kan det legges inn kommentarvinduer og pauser. Hastigheten til utførelsen av tastetrykkene kan også angis. Dette er en god mulighet til å lage pedagogiske opplegg rundt en tekst, se figur 9.
Et separat program, COLLGEN, kan generere sammenstillinger av ord som opptrer flere ganger (kollokasjoner). Det er mulig å angi maksimalt antall ord i sammenstillingen og minimumfrekvens.
Søkingen i ordlisten tar noe lenger tid en med WordCruncher, hvor oppslaget er mer eller mindre umiddelbart. Versjon 1.2 går også ut i feil pga. for lite hukommelse dersom en prøver å se på kontekster til et ord eller en gruppe som har mer en ca. 3.000 forekomster, bruker en komplisert søkemaske eller prøver å finne for lange ordsammenstillinger. Programmene kan ikke gjøre bruk av ekstra hukommelse utover 640K. Dette er imidlertid feilsituasjoner som utviklerne jobber med. Programmet får også problemer dersom et ord har mer en 65.000 forekomster, da blir frekvensopplysningene i ordlisten feilaktige og etterfølgende ord i ordlisten får feil kontekst.
Til TACT medfølger det en manual på 177 sider og en eksempeldatabase som brukes som illustrasjon i manualen. Programmet virker gjennomtenkt og har kvaliteter som går ut over kommersielle programmer som OCP og WordCruncher. I senere versjoner blir forhåpentligvis programmet mer robust mht. brukergrensesnitt og administrasjon av hukommelse.
TACT distribueres fra Senteret med manual til selvkost for 250 kr. inkl. porto. Beløpet kan betales til postgirokonto 0802 3384567 eller bankgiro 3625.88.53657 merket TACT. Programmet kan også hentes via anonym FTP fra maskinen nora.navf-edb-h.uib.no (129.177.24.42) i katalogen /pub/pc/tact.
FIGURER