Programvarene som Centre for New
OED har utvikla, byggjer på Unix-operativsystemet som kan køyrast
på den nye generasjonen av datamaskiner. For å nytte ut samverknaden
mellom PAT, som finn førekomstane og LECTOR, som syner dei i det
ønskte formatet, må ein ha skjerm med vindaugsfunksjon. Desse
programvarene er no til sals gjennom firmaet Open Text og er presenterte
som Open Text Managements Tools. Programpakken (PAT, LECTOR, TTK) for ein
arbeidstasjon kostar i dag $1800 (Cdn) for vitskaplege institusjonar. Ein
lisens for heile universitetet kjem på $18.000 (aug. 1990).
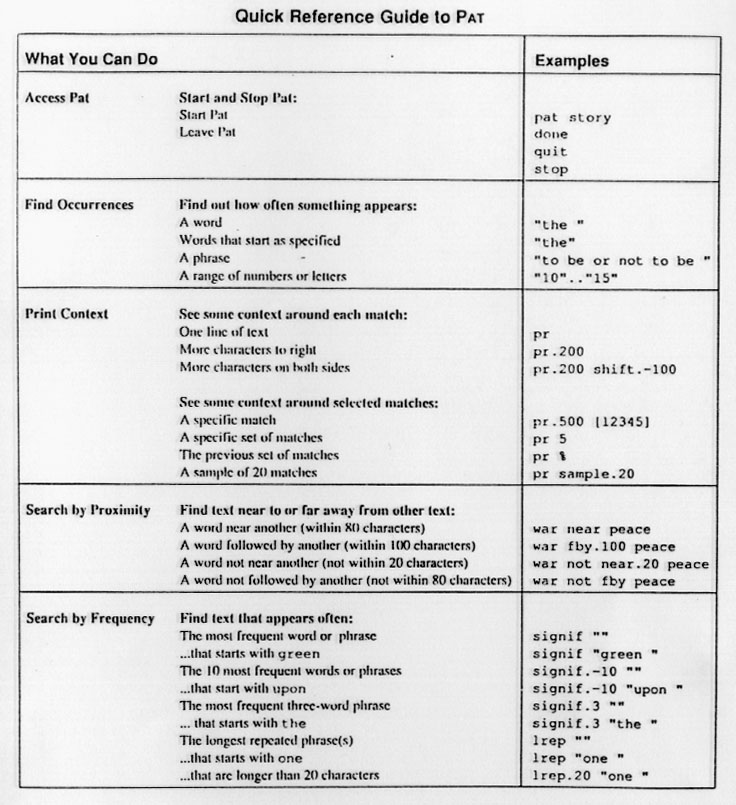

Som ordsamlar og ordboksskrivar er
eg først og fremst imponert over at datafolka ved Centre for OED
i samarbeid med ordboksredaksjonen i Oxford, England, verkeleg tok datagrunnlaget
som dei skulle forme ut databaseopplegg for, på alvor. Databaseutforminga
byggjer på særdraga i tekst, ikkje på ei tilpassing til
databasar for andre datatypar. Difor er programvarene høvelege arbeidsreiskapar
som ikkje gjer vald på dataene, og du får ut at den informasjonen
du legg inn, alfabetisk som i ordboka og arkiva. Dertil kan ein få
ut ei rad nye informasjonskombinasjonar frå heile materialet, som
er til støtte i ordboksarbeid og ein føresetnad for allmenn
informasjonssøking. Men det er ingen snarveg til ein tenleg elektronisk
tekstdatabase. Dersom materialet ikkje kan gjerast tilgjengeleg gjennom
optisk lesing, må det tastast inn, og innskrivarane må vere
i stand til å merkje ut visse hovuddrag i strukturen. Då først
kan ein setje i gang med tekstbehandling med hjelp av programvarene frå
Open Text. Datafolka ved Centre for New OED skil difor mellom maskinleseleg
("machine readable") tekst og tekst som er strukturmerkt etter programbehandling
("computerized text"). I ein tekstdatabase for frisøking må
dataa vere strukturmerkte etter programbehandling.
Kravet som blir stilt til oss ordboksfolk,
er at vi lagar ein grov "grammatikk" som ordartiklar og innsamla ordtilfang
skal strukturmerkjast eller taggast etter.
Til den som ventar på bodskapen
om at datamaskinene skal ta over tankearbeidet i leksikografien, har eg
inga trøyst. Datastødd leksikografi legg heller ei ny arbeidsoppgåve
på ordboksfolket med strukturmerkinga. Men frå før veit
vi at datastødde arbeidsmåtar gjev oss betre kontrollrutinar.
Sett ifrå brukarsynstad blir ein tekstdatabase til oppslagsbruk ei
informasjonskjelde med umåteleg mange innfallsportar. Informasjonen
kan gjelde både sjølve teksten og den røyndomen som
teksten refererer til. Såleis kan eit søk i OED-basen fortelje
at teiknsekvensen "Norway" er brukt 597 gonger. Når ein så
kallar fram desse førekomstane anten i kontekst eller som ordbokstekst,
ser ein at i denne ordboka er landsnamnnet vårt ofte brukt til å
lokalisere stein og mineral (t.d. som finnestad for cenosite og
euxenite). OED stadfester dermed at Noreg først og fremst
er ei steinrøys!
Elles var det gildt å prøve
desse programma på norske data. Frå senteret logga vi oss inn
på KARI på USE og forsynte oss med ei fil frå databasen
til Nynorskordboka, som er på 10 MB og inneheld 97 filer.
Denne fila med data frå byrjinga av bokstaven t, tok det fire minutt
å føre over Atlanteren. Etter at fila var behandla med TTK,
kunne det søkjast med PAT og resultata kunne visast i LECTOR. Såleis
er frasen "som gjeld" brukt 27 gonger i denne fila, t.d. i definisjonane
under taiwansk og teknisk. Jamfør elles vedlegget
på s. 66 og 67 for skrante frå Norwegian Dictionary
(= Nynorskordboka). Heimenorsk går like godt som engelsk. Elektronisk
tekst er internasjonal!
Kjernen i det datafolka ved Centre
for New OED har gjort, ligg i databaseutforminga. Ein einstrengs database
for store datamengder som er tilgjengelege samstundes, og som svarar snøgt
på spørsmåla som blir stilte, stettar dei hovudkrava
ein må stille til ein tekstdatabase til kunnskapslagring og -formidling.
Prosjektet med å gjere OED datatilgjengeleg viser òg at det
må vere eit forpliktande samarbeid mellom datafolk og filologar
(humanistar) for å få tenlege løysingar i humanistisk
databehandling.
Litteratur som eg fekk om New OED-prosjektet:
-
Rick Kazman: Structuring the Text of the Oxford English Dictionary
through
-
Finite State Transduction, June, 1986.
-
Gaston H. Gonnet: Examples of PAT applied to the Oxford English
-
Dictionary, July, 1987.
-
Darrel R. Raymond and Yvonne Warburton: Computerization of Lexicographical
-
Activity on the Oxford English Dictionary, August, 1987.
-
Gaston H. Gonnet and Frank Wm. Tompa: Mind Your Grammar: a New
Approach to
-
Modelling Text, March, 1987.
-
Gaston H. Gonnet and Frank Wm. Tompa: Hypertext and the New Oxford
English
-
Dictionary, November, 1987.
-
Timothy Benbow, Peter Carrinton, Gayle Johannesen, Frank Wm. Tompa
and Edmund
-
Weiner: Report on the New Oxford English Dictionary User Survey,
-
November 1, 1987.
-
Donna Lee Berg, Gaston H. Gonnet and Frank Wm. Tompa: The New
Oxford English
-
Dictionary Project at the University of Waterloo, February,
1988.
-
Gaston H. Gonnet: Efficient Searching of Text and Pictures
Extended
-
Abstract, June, 1988.
-
Information in Text Fourth Annual Conference of the UW Centre
for the
-
New Oxford English Dictionary. Proceedings of the Conference, October
26-28,
-
1988. Waterloo, Canada.
-
R.A. Baeza-Yates and Gaston H. Gonnet: Efficient Text Searching
of Regular
-
Expressions (Preliminary version) April, 1989.
-
Donna Lee Berg: The Research Potential of the Electronic OED2
Database at
-
the University of Waterloo: a Guide for Scholars, May, 1989.
-
Frank Wm. Tompa and Darrell R. Raymond: Database Design for a
Dynamic
-
Dictionary, June, 1989.
-
Heather Fawcett: Using Tagged Text to Support Online Views,
July,
-
1989.
-
Heather Fawcett: Adopting SGML: The Implications for Writers,
July
-
1989.
-
Dictionaries in the Electronic Age Fifth Annual
Conference of the UW
-
Centre for the New Oxford English Dictionary. Proceedings of the
Conference,
-
September 18-19, 1989. St. Catherine's College. Oxford, England.
-
G.V.J. Townsend: Citation Matching in the Oxford English Dictionary,
-
October, 1989.
-
Heather Fawcett: PAT 3.3 User's Guide. 1989
Heilt til slutt hermer eg datafolket om kvar vi står i dag i kunnskapsformidlinga
gjennom ordboksarbeid, og kvar vegen vidare går:
A meticulously crafted book is evidence of the value of interweaving
presentation and representation in a single, inseparable whole. A meticulously
crafted database is evidence of the value of separating presentation and
representation, achiving flexibility in both. Addressing the tension created
by these two incompatible forms is the key step in designing the dynamic
dictionary of the future.
Tompa & Raymond, June, 1989:15
Dagfinn Worren er førsteamanuensis ved Institutt for
nordistikk og litteraturvitskap, Avdeling for leksikografi, Universitetet
i Oslo.
Figurar.


