Building a Spoken Corpus of Slovene
Final Report on a Marie Curie
Training Site host PhD fellowship at the Bergen Advanced Training Site in
Multilingual Tools (BATMULT), University of Bergen, September 15 – December 15,
2004
Jana Zemljarič Miklavčič,
Project description
My PhD research is aimed at theoretical
foundation on building a spoken corpus of Slovene language, which is planned to
complement the 100 million word FIDA corpus (http://www.fida.net/slo/index.html)
as its spoken component. There are two main scientific challenges in my
research: the first is to develop a set of criteria for the collection and
selection of spoken material to be included in a representative and balanced spoken corpus, and the
second is to outline the recommendations for the transcription and annotation of a spoken texts. As to the criteria for collection, a
preliminary proposal for the selection of materials, based on the combination
of the demographic and contextual method has been already worked out. The
actual collection of spoken texts has also been started before coming to Batmult.
The main aim of my three months stay at Batmult as a Marie Curie Host PhD student was to compile a pilot
spoken corpus of Slovene based on digital recordings, available in searchable
form, with transcriptions linked to sound files. The purpose of a pilot corpus
was to redefine the
criteria for the collection, selection and documentation of spoken materials, to
develop and test transcription and mark-up conventions, and finnally
to show some possibilities for the use of a corpus for language description and
language analysis. Batmult training site at The Department
of Culture, Language and Information Technology (AKSIS) at the
Concrete Achievements and Results
The design of a pilot corpus
Slovene language is spoken by 2 million
speakers in
The pilot corpus consists of 7 digital
recordings in total length of 89 minutes. All texts were recorded in year 2004.
The specification of the recordings is shown in the following table:
|
ID |
Duration
min |
No. of speakers |
Place of recording |
Surreptitious |
Genre |
|
R01 |
2.17 |
2 |
University |
No |
interview |
|
R02 |
54.50 |
6 |
Studio |
No |
round
table |
|
R03 |
3.58 |
2 |
Home |
No |
interview |
|
R04 |
7.31 |
5 |
Office |
No |
spont. convers. |
|
R05 |
3.23 |
5 |
Skate-park |
No |
interview |
|
R06 |
11.54 |
3 |
Workplace |
No |
spont. convers. |
|
R07 |
5.12 |
2 |
Home |
Yes |
spont. convers. |
|
å=7 |
89.00 |
|
|
|
|
Table 1: Pilot corpus recording's documentation
All
information about speakers has been collected on speaker’s identity lists. The
data are represented in following table:
|
ID |
Sex |
Year of Birth |
Age |
Education |
Region |
|
G01 |
F |
1963 |
41 |
University |
Central |
|
G02 |
M |
1965 |
39 |
University |
Central |
|
G03 |
F |
1966 |
38 |
University |
Central |
|
G04 |
F |
1967 |
37 |
University |
Central |
|
G05 |
F |
1968 |
36 |
University |
Central |
|
G06 |
F |
1968 |
36 |
University |
Central |
|
G07 |
M |
1970(?) |
34(?) |
University |
Other |
|
G08 |
M |
1933(?) |
71(?) |
University |
Central |
|
G09 |
F |
1979 |
25 |
University |
South-east |
|
G10 |
F |
1967 |
37 |
High school |
North-west |
|
G11 |
M |
1987(?) |
17(?) |
Primary sch. |
Central |
|
G12 |
M |
1987(?) |
17(?) |
Primary sch. |
Central |
|
G13 |
M |
1987(?) |
17(?) |
Primary sch. |
Central |
|
G14 |
F |
1976 |
28 |
University |
South-east |
|
G15 |
F |
1979 |
25 |
University |
Central |
|
G16 |
M |
1978 |
26 |
High school |
Central |
|
G17 |
M |
1978 |
26 |
High school |
Central |
|
G18 |
F |
? |
? |
? |
? |
|
G19 |
F |
1969 |
35 |
University |
North-west |
|
G20 |
M |
1948 |
56 |
High school |
North-west |
Table 2: Pilot corpus speakers' documentation
The sample of 20 speakers is representative
according to the sex of the speaker but not according to other demographic criteria.
The actual spoken corpus should consist of texts representatively taken from 5
areas that represent 5 dialectal groups of Slovene language. Furthermore there
should be 3 age classes and 3 educational classes. The rather opportunistic
nature of a pilot corpus should be taken into consideration when analyzing it.
Pilot corpus is better designed in the concern
of contextual criteria: different structure types, settings, speaker's positions,
genres and media are represented among the texts. However, the telephone conversations
and some other text genres should necessary be added to the planned spoken
corpus. The final design of the pilot corpus according to contextual criteria is
presented in following table:
|
Contextual criteria |
Proportion |
|
Dialogue
(or multilogue) vs. Monologue |
94 % : 6 % |
|
Private
vs. Public |
19,5 % :
80,5 % |
|
Informal
vs. Formal |
35,5 % :
64,5 % |
|
Media vs.
Face to face |
31 % : 69 % |
|
Surreptitious
vs. Nonsurreptitious |
5,6 % : 94,4 % |
Table 3: Texts according to selected contextual
criteria
Transcribing
I have learned about existing transcription
software at Batmult, and tested three programs, Praat, Transcriber and WinPitch.
According to their characteristics I've decided to use the first two mentioned
to carry out actual transcription work. Transcriber is a tool for segmenting,
labeling and transcribing speech; I found it more user-friendly than Praat, however, it doesn't allow transcribing overlapping
speech of more than two speakers.
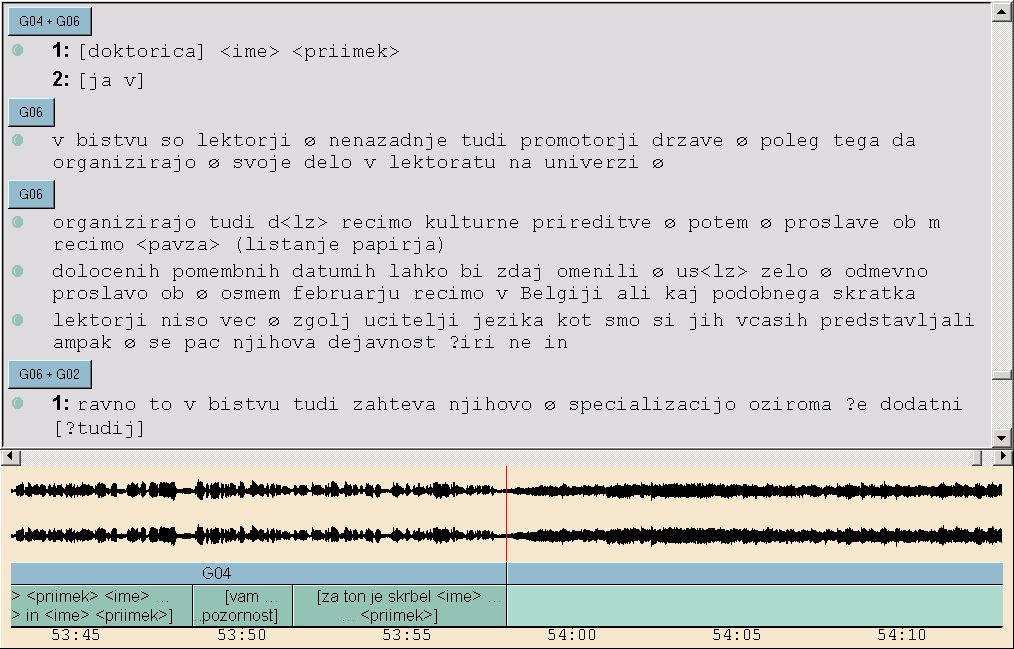
Picture 1: Transcriber
working platform,
transcription of a pilot spoken corpus of Slovene
Program Praat, on the
other hand, is less suitable for transcribing and works very slowly for longer
recordings (more than 30 minutes) but it allows transcribing overlapping speech
of more than two speakers which is often the case with spontaneous speech.
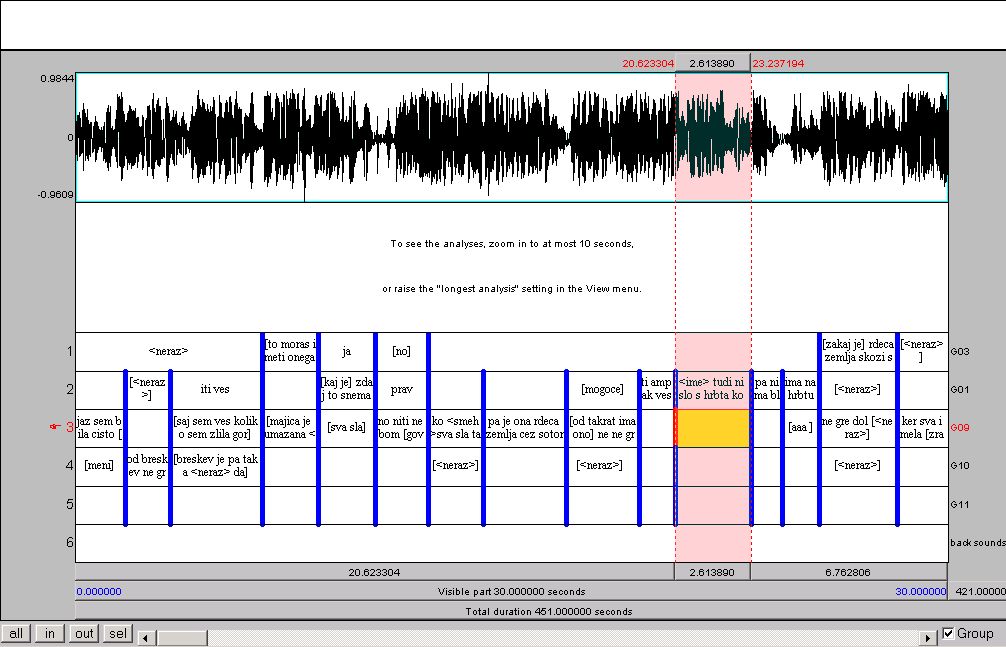
Picture 2: Praat platform, transcribing for a pilot spoken corpus of Slovene
Both programs enable an automatic
synchronization of transcriptions and sound clips. In WordPad format of
transcriptions (either made in Transcriber or Praat)
speakers’ utterances are clearly marked within a time coding, as shown on a
following example:
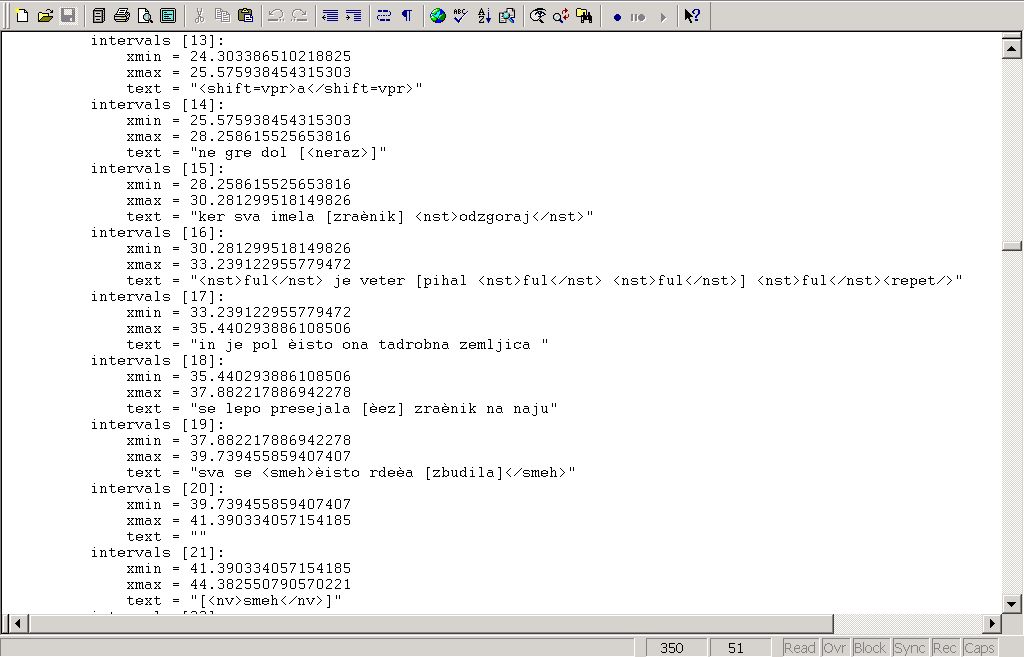
Picture 3: Transcription, done in Praat program, in WordPad format
Transcription standard
During actual transcription work I had to
decide about transcription principles for transcribing spoken Slovene language.
I was following the TEI and EAGLES recommendations on transcribing and
annotating spoken texts. As commonly experienced when creating spoken corpuses
I decided for an individual form of modified orthographic transcription. Basic unit of a speech is an utterance,
defined by a short pause or a speaker turns. No punctuation is used in
transcription, capital
letters are used for proper names only.
The adopted
transcription standard is presented on the following scheme:
|
Tag |
Meaning |
|
<pavza> <pravza>(5) <ime> <priimek> <priimek><f> <neraz> <neraz>
(5) <?> text </?> <lz> <repet> <nst>word</nst> <okr>word</okr> [text] <singing>text</singing> <shift=vpr>text</> <shift=poud>text</> <tj: norv>text</tj> <nv>laughing</nv> (description) <??> text</??> |
short
pause (app. 1 sec) pause (5
sec) personal
name family
name family
name, a form for women unintelligible
unintelligible
(5 sec) uncertain
transcription false
start, truncated word repetition non-standard
word or form acronym
or abbreviation overlapping
speech paralinguistic
markers part of
the text, recognised as a clear question emphasised,
stressed a word or
a text spoken in foreign language nonverbal
events non
communicative background sound speaker
unknown or uncertain |
Table 4: Transcription standard used in Pilot
Spoken corpus of Slovene
Converting transcriptions into a searchable
corpus
The conversion of transcriptions, linked to sound files, into a searchable corpus, has been made by
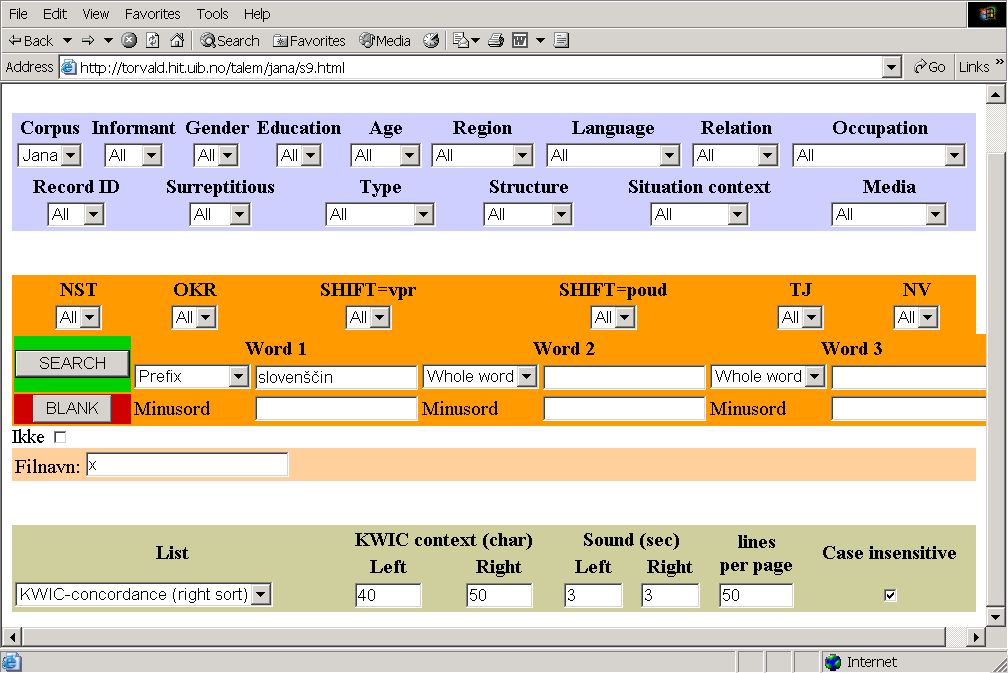
Picture 4: Aksis
Corpus Bench, Pilot Spoken Corpus of Slovene (Corpus Jana)
Corpus Analysis
Building a corpus of course involved a lot of
transcription and annotation work. For 89 minutes of recordings I spent about
100 hours for actual transcription work. Additional time has been spent for
many revisions while deciding about transcription standard. The size of a
corpus is about 15.000 tokens – words and prosodic (<pause>) and
non-linguistics (<nv>laughing</nv>) tags. The
first version of a pilot corpus, derived from 3 recordings, has been put on Aksis corpus bench in mid November,
however the necessary revisions have been made since then almost every day
until my final day at Batmult. That explains that
accurate analysis of a pilot corpus will follow at my further study. However
some examples of a use of a corpus can be shown even at this stage of work.
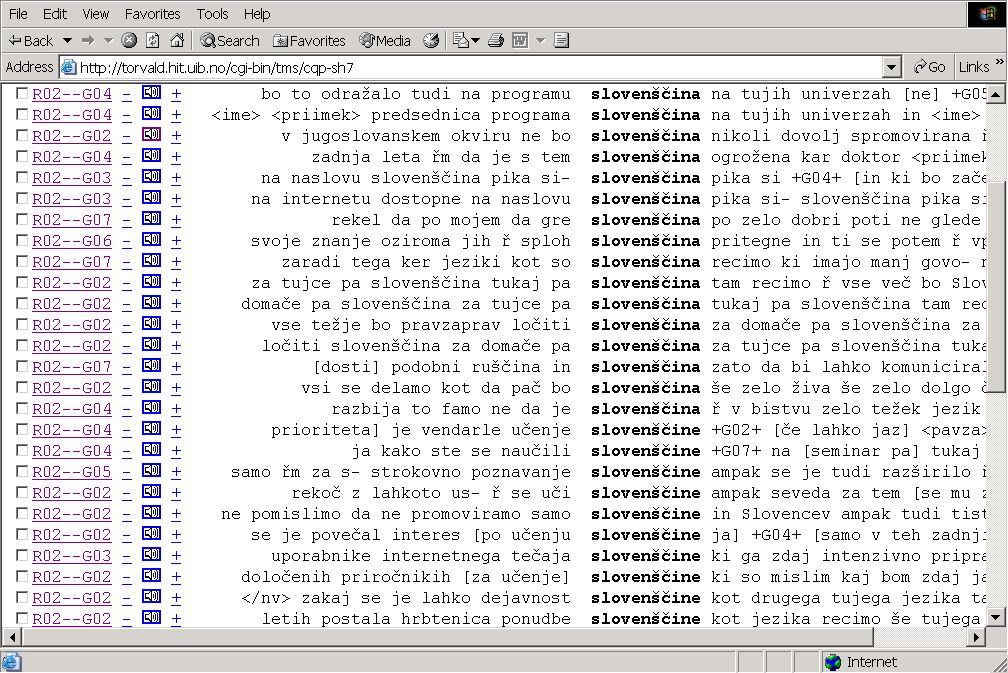
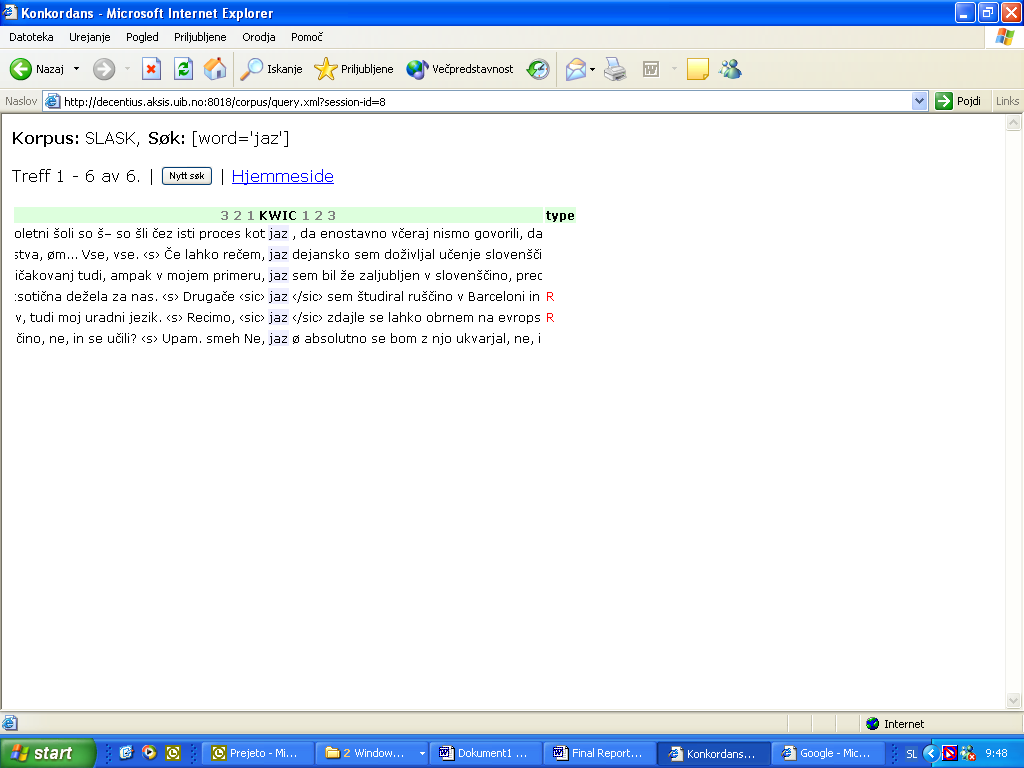
Picture 5: Pilot Spoken Corpus of Slovene, concordance
of "slovenščina"
On the Picture 5, the concordance of the word
"slovenščina" (Slovene language) can be
observed. The whole utterance is linked to the actual sound file and attributed
with speaker and record identification (G, R). The three special Slovene characters
(č, ž, š) that presented a problem at one stage of conversion have been already
properly used in this extract.
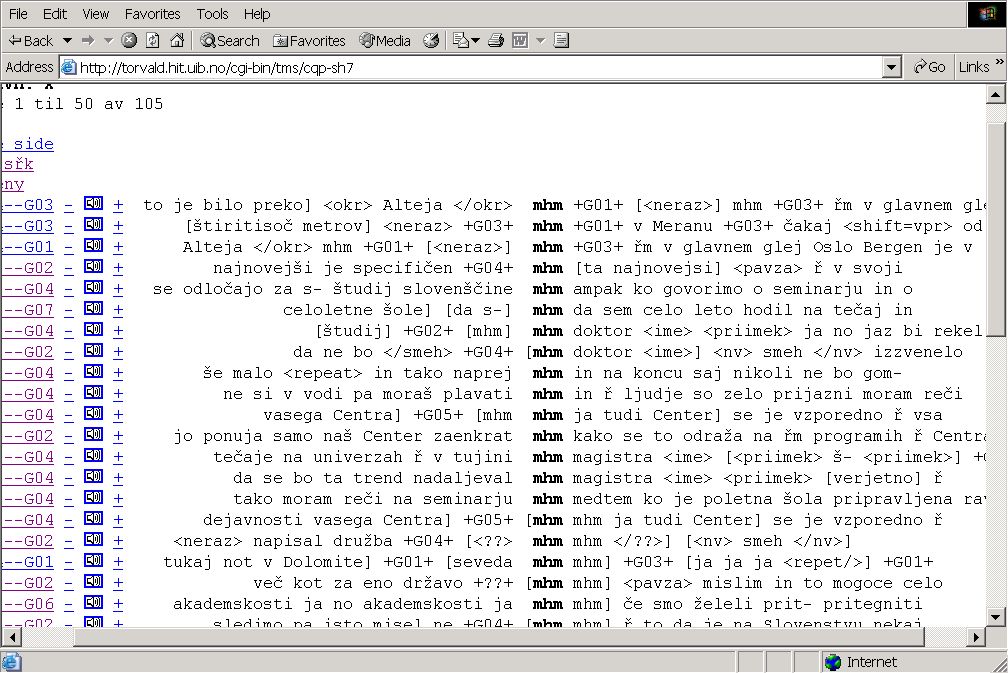
Picture 6: Pilot Spoken Corpus of Slovene,
concordance of "mhm"
The discourse marker "mhm"
has, as expected, very high absolute frequency (105) comparing to it's absolute frequency in ten thousand times bigger corpus Fida (156). With the pilot corpu
we could argue the explanation of a meaning of the word "mhm" in Slovene standard dictionary: it is explained
as a word of hesitation or a word of restrained agreement. We can not find even
one example to prove that explanation among 105 mhms
in the pilot corpus, however some highly represented meanings should be added
to the explanation in the dictionary.
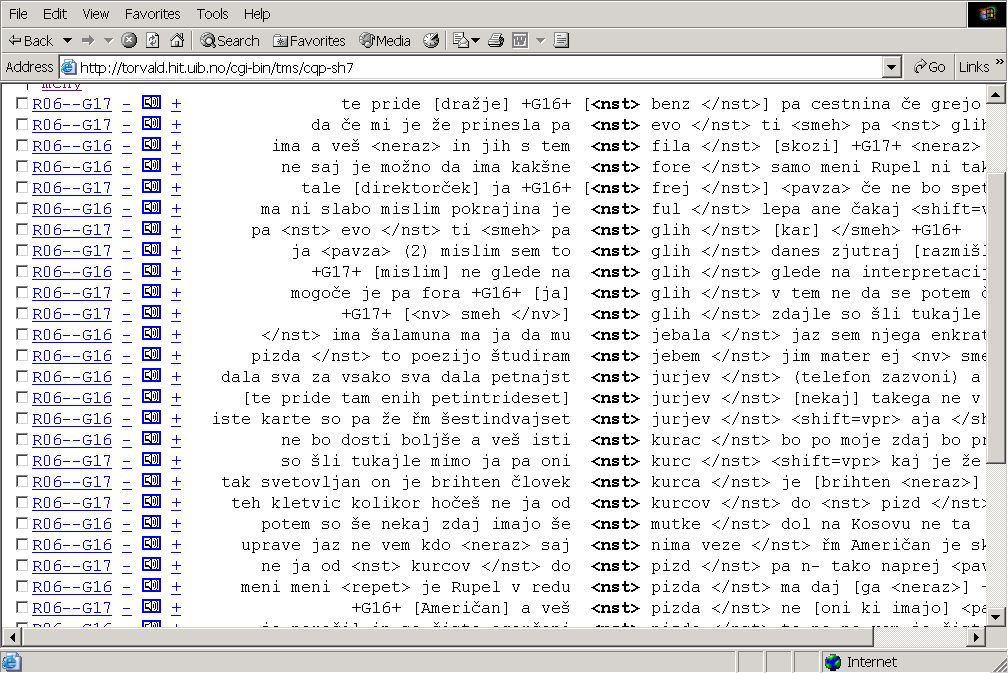
Picture 7: Pilot Spoken Corpus of Slovene,
concordance of tag "<nst>"
"Non-standard word" is an annotation
mark, difficult to define by empirical criteria; it's
definition certainly needs further consideration. However, the pilot corpus
shows the set of words that somehow resign, at least to my language intuition,
from standard language. Among them we could find a lot of vulgar words, words
from slang and dialects and words of foreign origin.
Frequency list